Requests & Limits avec VPA, Goldilocks et Grafana
Sommaire
Lorsqu'on développe des applications Cloud Native qui seront hébergées sur Kubernetes, on doit toujours paramétrer et optimiser l'utilisation du CPU et RAM des déploiements.
Si cela n'est pas fait, on peut arriver dans des situations délicates, comme ne pas avoir assez de ressources disponibles si un serveur (node) est indisponible, quelques process OOMKilled à cause de limites de mémoire trop restrictives, des pods non schedulés, etc. De plus, par défaut, certaines valeurs de déploiements ne sont pas toujours alignées avec l'utilisation que l'on en a (comme certains charts Helm publics).
Alors, comment valider nos déploiements, et adapter les Requests & Limits pour coller au mieux à l'utilisation que l'on en a ? Cela peut être fait avec un mix d'outils Open Source, que l'on verra dans cet article.
Vertical Pod Autoscaler
Kubernetes Vertical Pod Autoscaler permet de suivre l'utilisation CPU et RAM des pods d'un cluster, et les adapter automatiquement si besoin. On retrouvera plus d'information ici : https://github.com/kubernetes/autoscaler/tree/master/vertical-pod-autoscaler
Le VPA a 3 composants: le Recommender, l'Updater et l'Admission Plugin. Dans notre cas, on ne souhaite avoir que des recommendations, alors on n'utilisera que le Recommender.
L'installation peut se faire de plusieurs façons, mais on utilisera ici le chart Helm fourni par Fairwinds.
Comme l'on utilise Prometheus comme outil de monitoring, on s'en servira plus tard de source pour récupérer les métriques VPA. On active cela dans les valeurs du chart Helm :
1$ helm repo add fairwinds-stable https://charts.fairwinds.com/stable
2$ helm repo update
3$ helm install vpa fairwinds-stable/vpa --namespace vpa --create-namespace -f vpa-custom-values.yaml # See below
1admissionController:
2 enabled: false
3recommender:
4 enabled: true
5 extraArgs:
6 prometheus-address: |
7 http://prometheus-operated.observability.svc.cluster.local:9090
8 storage: prometheus
9updater:
10 enabled: false
Comme dit plus haut, Prometheus est utilisé ici comme fournisseur de métriques, pour avoir des informations plus pertinentes, et permettant d'avoir un historique plus grand. On ne couvrira pas l'installation de l'outil dans cet article.
Maintenant qu'on a le VPA fonctionnel (du moins, le recommendeur), on peut créer une configuration VPA. Un exemple est disponible ici.
La définition d'un VPA est assez simple, mais souhaitant plus d'automatisation, on va utiliser Goldilocks !
Goldilocks
Goldilocks est un utilitaire de la société Fairwinds, qui va permettre de gérer les requêtes et limites simplement, basé sur les VPA, comme précédemment installé.
L'outil va vérifier les déploiements, et automatiquement créer les VPA en fonction de labels. Donc si l'on souhaite activer les VPA sur un déploiement, un namespace ou une autre resource Kubernetes, il suffit d'y ajouter un label, et Goldilocks fera le reste !
L'installation se fait avec un chart Helm :
1$ # Goldilocks Helm repository is already there
2$ helm install goldilocks --namespace vpa fairwinds-stable/goldilocks
Une fois Goldilocks déployé, on retrouve 3 pods :
- Goldilocks controller, qui scrute les labels et créer les VPA en conséquence.
- Goldilocks dashboard, qui permet d'avoir un dashboard standalone pour voir les reommendations VPA.
- VPA recommender, qui calcule les recommendations sur les Requests et Limits CPU et RAM.
1$ kubectl get pods
2NAME READY STATUS RESTARTS AGE
3goldilocks-controller-5bf99 1/1 Running 0 49d
4goldilocks-dashboard-699f4 1/1 Running 0 49d
5vpa-recommender-74fdc 1/1 Running 0 67d
Maintenant, il suffit de rajouter le label qui va bien (goldilocks.fairwinds.com/enabled=true) sur un namespace pour voir la magie opérer : on ajoute ici les labels sur le namespace "velero", et les VPA seront automatiquement créés :
1$ kubectl label ns velero goldilocks.fairwinds.com/enabled=true
2$ kubectl get namespace velero --show-labels
3NAME STATUS AGE LABELS
4velero Active 112d goldilocks.fairwinds.com/enabled=true,name=velero
5
6$ kubectl get vpa -n velero
7NAME MODE CPU MEM PROVIDED AGE
8goldilocks-restic Off 15m 183046954 True 67d
9goldilocks-velero Off 11m 183046954 True 67d
Note: Fairwinds propose aussi un chart Helm qui installe les VPA et Goldilocks en même temps, mais ne le recommendent pas.
Maintenant que l'on a nos VPAs créé automatiquement, on peut voir les recommendations sur le dashboard dédié !
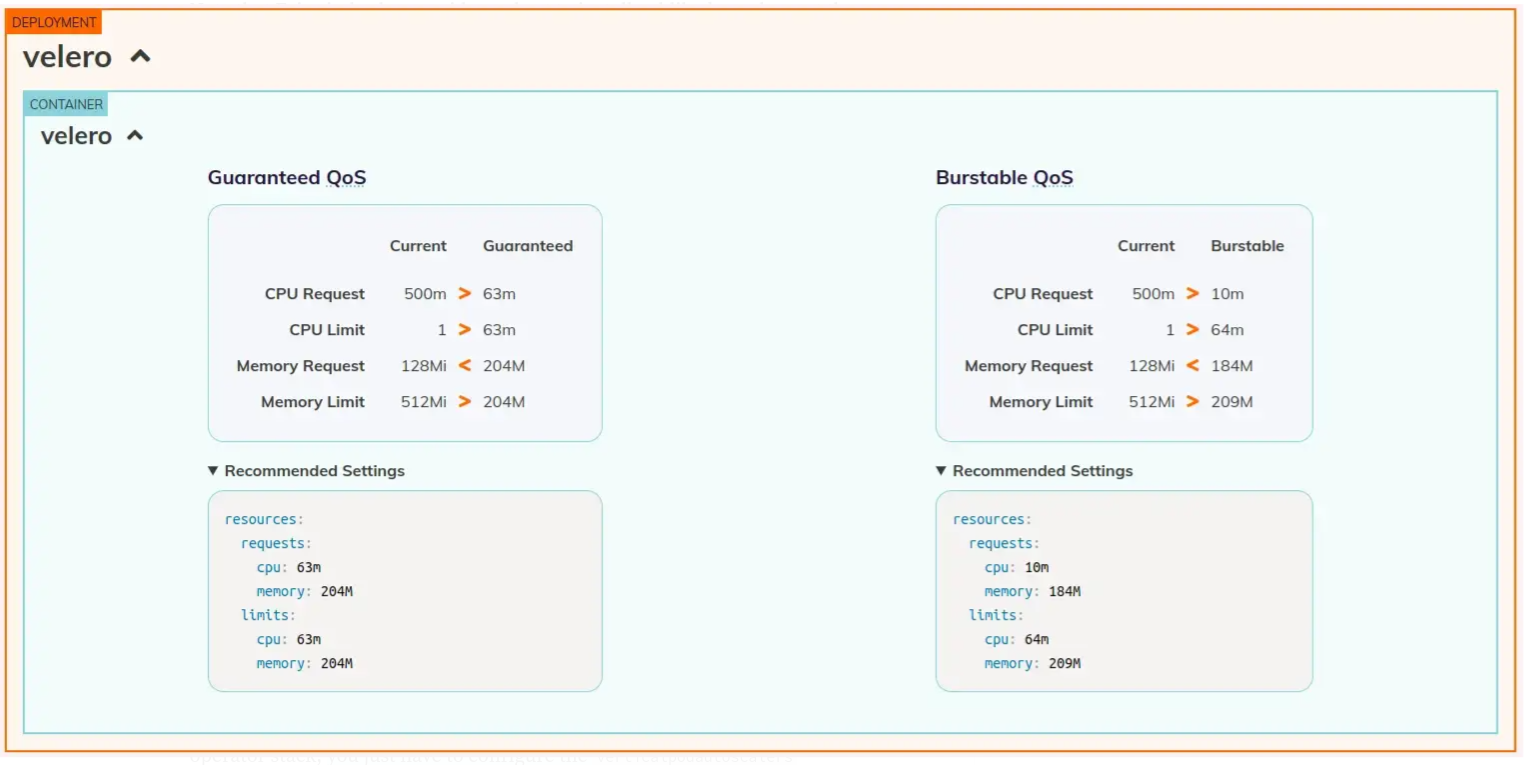
OK, c'est très bien, mais on a généralement déjà de beaux tableaux de bord avec des outils de monitoring comme le couple Prometheus & Grafana. Pourquoi ne pas les utiliser au lieu du dashboard dédié ? On y va !
Prometheus & Grafana
En cherchant un peu dans les paramètres des VPA et les métriques disponibles, on peut voir que kube-state-metrics expose les informations suivantes :
kube_verticalpodautoscaler_status_recommendation_containerrecommendations_lowerboundkube_verticalpodautoscaler_status_recommendation_containerrecommendations_upperbound
Toutes ces métriques sont définies ici.
Si on utilise l'opérateur Prometheus, il faudra le mettre à jour pour explicitement activer le collecteur verticalpodautoscalers dans le déploiement kube-state-metrics.
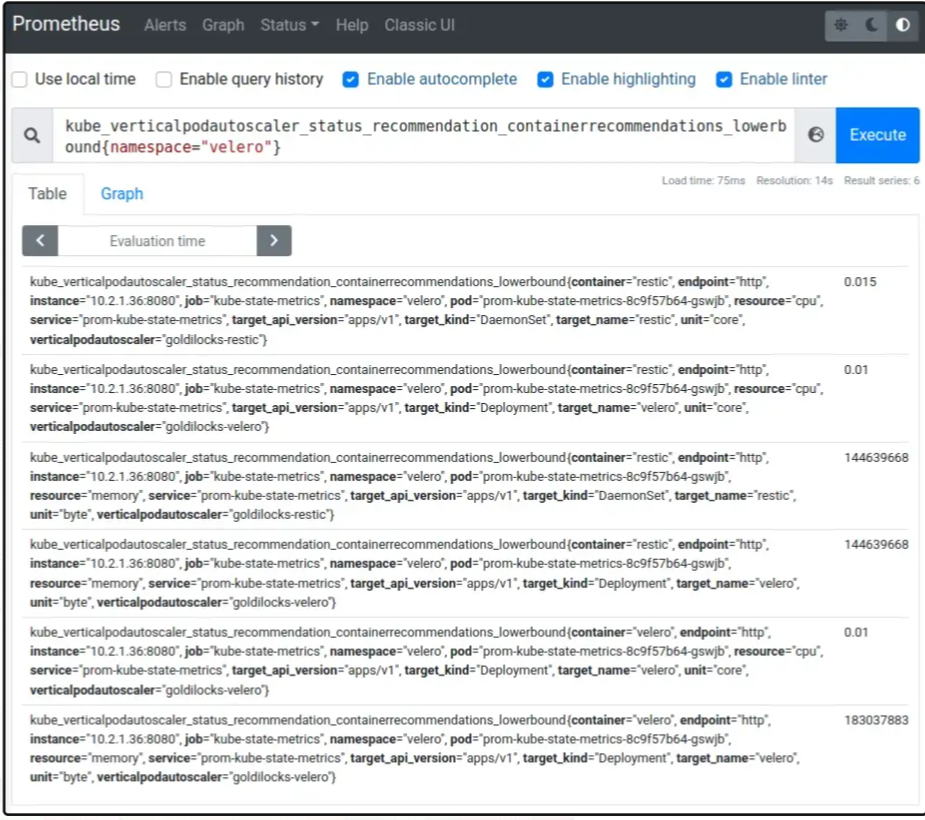
On a maintenant les VPA, les métriques Prometheus, on peut donc arêter le dashboard Goldilocks et créer le notre dans Grafana, et récupérant les bonnes métriques !
- On va donc mettre à jour le déploiement de Goldilocks pour désactiver le dashboard :
1$ helm upgrade goldilocks --namespace vpa fairwinds-stable/goldilocks -f goldilocks-custom-values.yaml
1dashboard:
2 enabled: false
- On crée un dashboard Grafana !
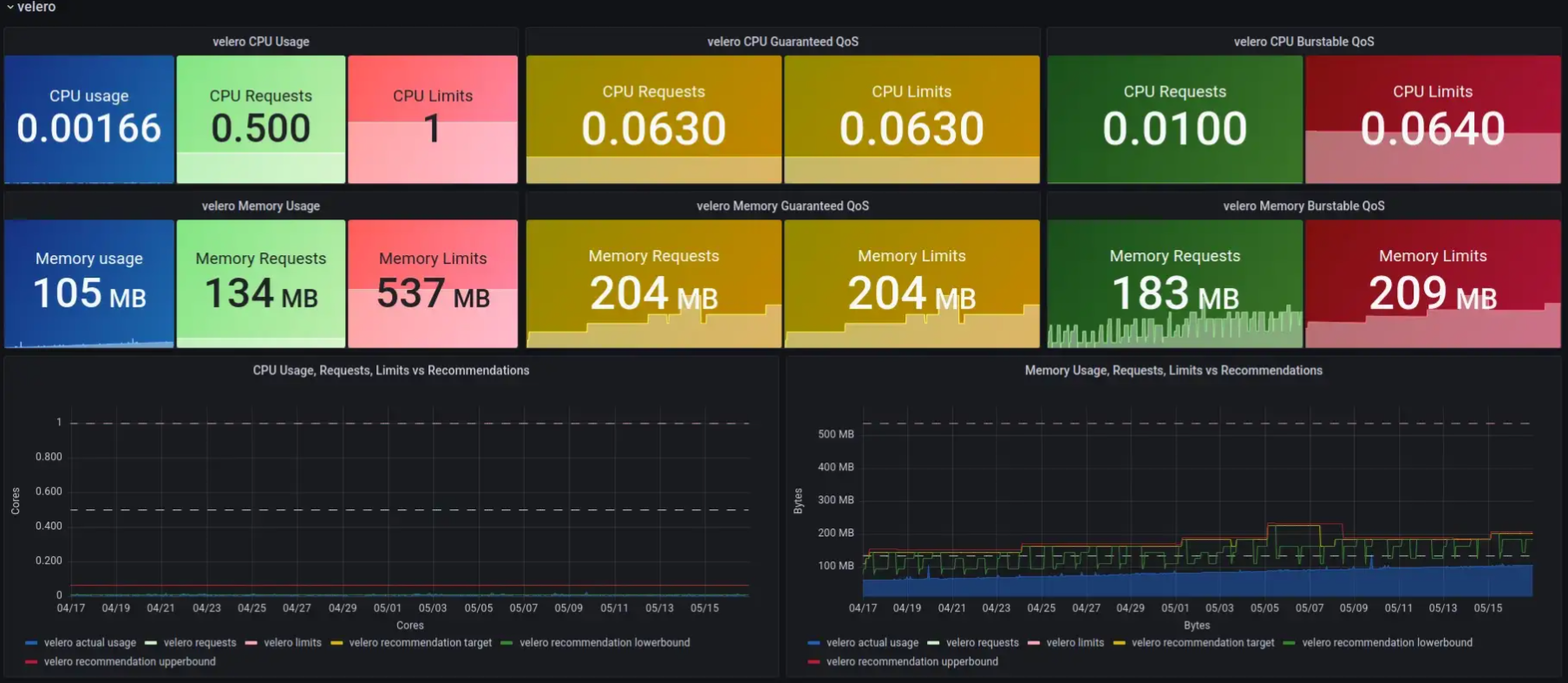
Cool ! On peut maintenant suivre et adapter les Requests & Limits de nos applications depuis notre outil de dashboard préféré, et adapter les différents seuils pour s'adapter au cluster. On peut aussi étendre l'historique des recommendations, pour mieux adapter les valeurs.
Un exemple de tableau de bord est disponible ici : https://grafana.com/grafana/dashboards/16294
Fun fact, j'ai utilisé Goldilocks pour adapter les Requests & Limits de Goldilocks lui-même ;)
Ressources
On peut récupérer un autre tableau de bord ici, lequel j'ai utilisé comme source pour crée le mien.